 if you have trouble).
if you have trouble).
| ↑↑ Home | ↑ Science |
Representation -- Caveats -- Correlation and compensation -- Type properties -- Exceptions -- Compiler issues -- Practical considerations -- References
Quite a lot of people, including scientists, use floating-point numbers assuming they are a faithful representation of mathematical real numbers. This assumption lives in the dangerous grey zone between outrageously false and actually true — it is true frequently enough that those times when it is not come as nasty surprises. This page intends to spread some knowledge about floating-point arithmetic that, while not very deep, is less widespread than it ought to be.
The following trivia about floating-point representation will hopefully keep you from ever seeing them as faithful to reals again:
There are only a finite number of different floats
While this is obvious, it puts paid to the idea of representing reals in general. Since the representation basically consists of storing integer or fractional digits in a given base, in fact all representable numbers are rationals.
Floats are discrete but not equidistant
Also a bit of a triviality. Any finite subset of the reals is discrete. Unlike integers, floats are dense close to zero, and rather thin on the ground at large moduli.
The diagram below shows the location of the finite numbers representable by a
hypothetical 8-bit floating-point format that has a 4-bit mantissa (with an
implied fifth leading 1 bit) and a 3-bit exponent but otherwise follows IEEE
conventions. Click on it for a scalable SVG image you can zoom into (in fact,
this is a bit of a test case for your browser's SVG support; view it offline
with inkscape if you have trouble).

You can see that the spacing between adjacent numbers jumps by a factor of two at every power of two larger than 0.25. 0.25 is the smallest normalised number in this representation (by modulus), and numbers between -0.25 and 0.25 are denormalised, indicated by the square bracket above the axis. The ±0.015625 printed above the zero are the smallest non-zero representable numbers. The zero exponent of subnormal (denormalised) numbers implies the same power-of-two multiplier as an exponent of one, or there would be a gap because subnormals lack the implied leading one bit.
Only (reduced) fractions with power-of-two denominators are representable accurately
Yes, really! This is because any other denominator gives rise to an infinite number of fractional digits in a binary representation, which of course cannot all be stored. Do you feel your expectations of floats coming down to meet reality?
Non-negative floats sort like integers
This is less well known. To make it clearer: If you interpret two non-negative floating-point numbers as integers with the same size and endianness, the result of a comparison between those integers will be the same as that of the floating-point comparison. This is a consequence of the fact that the exponent is located in higher-order bits than the significand, and that the implied leading one bit of the significand does not affect comparisons. This does not account for NaNs (though it holds for positive infinity).
Negative floats have the inverse sorting order of the corresponding negative integers.
This has the interesting implication that under the restrictions above, it is possible to find the upper or lower neighbour of a floating-point variable by an integer increment or decrement:
++ *(int64_t*) &double_variable; /* successor */ -- *(int32_t*) &float_variable; /* predecessor */
By handling negative numbers properly, one could write functions that return
the successor or predecessor of any floating-point value. Indeed, the D
programming language provides such
methods for floating-point types.
The figure below shows the correspondence between our hypothetical 8-bit floating-point type and unsigned integers.

As you can see, the positive and negative float values are monotonically increasing with their integer counterparts. ±0.25 is the smallest normalised number by modulus, as noted above. There are more numbers above 1 (modulus) than below, because 1 is the smallest number with the middle-of-the-range exponent. The largest representable exponent indicates either infinity (for zero mantissa) or NaN, so the chance of hitting a NaN when generating data at random is rather higher than one would expect.
Take care converting large integers
64-bit integers may not fit into a double. Unless you know only 53 bits
are used, the only suitable floating-point type is the
80-bit extended precision
format (long double) on x86 processors.
(long double) on x86 processors.
Careful with iterations
In many if not most cases numerical computations involve iteration rather than just the evaluation of a single formula. This can cause errors to accumulate, as the chance of an intermediate result not being exactly representable rises. Even if the target solution is an attractive fixed point of your iteration formula, numerical errors may catapult you out of its domain of attraction.
Rounding
In addition to the rounding errors introduced at every step in a computation, the values your processor computes for transcendental functions may be off by more than basic arithmetic. This is because optimal rounding to the nearest representable number requires distinguishing on which side of the middle between them (an infinitely narrow line) the true result lies. Transcendental functions are power series with infinitely many non-zero coefficients, so one cannot really know that for a given argument without computing an infinity of terms of the series.
Non-power-of-two integer factors between fractional numbers are inexact
In the previous section, we learnt that most fractional numbers cannot be represented exactly. In addition, fractional numbers differing by an integral factor that is not a power of two will have a different relative error (as at least one of them will not be exactly representable). This means that choosing different units for the input to your calculation, such as metres versus millimetres, may get you a different result. Equality comparisons between quantities computed from input differing in that way may fail.
Additions are more problematic than multiplications
Floating-point multiplications are pretty much optimal, with the significands being multiplied and the exponents added, and the surplus least significant bits being discarded. An addition, by contrast, may have no effect at all if the numbers are too different. The reason for this lies in the fact that the distribution of representable floating-point values resembles a logarithmic scale more than a linear one (see the first figure above).
As a consequence, the simplest problem to provide unexpected results is adding up a series of numbers by the naive algorithm of successively adding them to a running sum variable. As the sum becomes larger, additions become increasingly inaccurate. The result can therefore depend on the order of the numbers. For addends of similar size, creating an adder tree (adding every two values, then recursively every two sums) is a possible fix, but rather complex to program. The following section will demonstrate an easier and more general solution.
Even more than simple addition, the computation of the mean and standard deviation shows the incompatibility of naive algorithms with floating-point numbers. For genuine real numbers the following formulas yield the correct result:
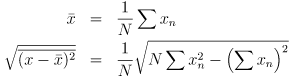
Computing the standard deviation from the sum and the sum of squares with floating-point numbers will however frequently get you a NaN, arising from a negative term in the square root, which in turn is caused by inaccuracies in the summation. Again, see the following section for a solution.
Sampling effects for trigonometric functions
The value of the sine function at 0 is 0, even numerically. But what is the next largest argument for which the numerical sin() returns zero? Actually I do not know either, but the number is certainly huge compared to 1. For double-precision floats finding this number would probably require years of computation time; for single precision there is no argument yielding 0 below the point where numerical trigonometric functions become meaningless. Run this program yourself to check.
The most readily noticed implication of this is that rotation matrices that
involve right angles have small non-zero entries where there should be zeros.
This is due to the numerical  differing slightly from zero. (For
the 1 entries, the corresponding discrepancy does not show up because of
rounding.) Generally, the periodicity of trigonometric functions is hidden by
the fact that differences between floating-point numbers are always an
irrational factor away from their period, 2π.
differing slightly from zero. (For
the 1 entries, the corresponding discrepancy does not show up because of
rounding.) Generally, the periodicity of trigonometric functions is hidden by
the fact that differences between floating-point numbers are always an
irrational factor away from their period, 2π.
What was this remark in the first paragraph about trigonometric functions becoming meaningless? When sampling functions uniformly, the highest frequency has to be below the Nyquist limit (half the sampling rate) for the function to be representable adequately. Floating-point numbers sample the real axis in a far from uniform manner (see the first figure again!). At some point the difference between adjacent floating-point numbers becomes larger than π — the equivalent of exceeding the Nyquist limit in uniform sampling.
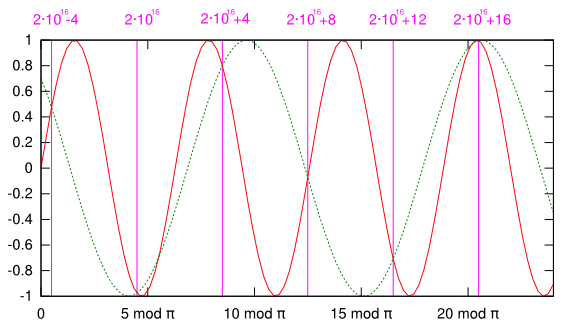
This figure shows the sine in red at the scale of large floating-point numbers
around 2·1016. The pink lines are successive numbers exactly representable in
double precision. The dotted green curve shows a sine with a period of
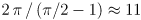 that has the same value as sin(x) at all
double-precision floating point numbers of this size or larger. The figure was
non-trivial to create. I used this program to find the
successor of a floating-point number and this Perl script to
compute the remainder mod 2π of any number exactly, to find out the position
of representable numbers relative to the sine.
that has the same value as sin(x) at all
double-precision floating point numbers of this size or larger. The figure was
non-trivial to create. I used this program to find the
successor of a floating-point number and this Perl script to
compute the remainder mod 2π of any number exactly, to find out the position
of representable numbers relative to the sine.
Let's start with the simplest example above, summation of a number series. A more accurate algorithm is the following (Kahan summation):
for all elements x in the number series
old_sum := sum
x := x - delta
sum := sum + x
delta := (sum - old_sum) - x
The method works as follows: The amount lost when updating the sum variable is computed by an expression undoing the summation, which would always result in 0 mathematically but does not because of numerical errors. Note the parentheses. This discrepancy is subtracted in the next run of the loop from the next element to be added, which unlike the sum is small enough for the subtraction to have an effect.
The important thing to take away from this is that numerical errors are not noise introduced at random in a computation, but can be quantified and possibly compensated.
[Aside: The Kahan summation algorithm can still fail when there are
cancellations much larger than the correct end result. See
here for even more robust
algorithms, a test case and link to a paper.]
A similar algorithm exists for computing the mean and standard deviation. This time delta is local to the loop body, but the other variables have to be initialised to 0 as above:
for all elements x in the number series
count := count + 1
delta := x - mean
mean := mean + delta / count
aux := aux + delta * (x - mean)
stddev := sqrt(aux / count)
This method is attributed to Welford and others.
This paper
contains a comparison of algorithms for computing the variance from a numeric
point of view, among others the one that yields the above for the standard
deviation (equation 1.3).
The standard C header file float.h contains preprocessor constants describing the details of your floating-point implementation, such as the size of the mantissa, the range of exponents, the maximum and minimum representable numbers, and others. Some of the constants are special representable numbers and can be marked on a simplified version of the scale above:

Normally the constants are prefixed with one of FLT_, DBL_ or LDBL_ for float (single precision), double or long double. I have left the prefix out for the purpose of presentation. The values of the most important constants for our 8-bit floating-point type are:
| Constant | Value | Explanation |
|---|---|---|
| EPSILON | 0.0625 | Difference between 1 and next larger representable value |
| MIN | 0.25 | Smallest normalised representable value |
| MAX | 15.5 | Largest positive representable value |
| MANT_DIG | 5 | Mantissa bit size including implied leading 1 |
| MIN_EXP | -2 | Minimum exponent for normalised number; also implied for subnormals |
| MAX_EXP | 3 | Maximum exponent |
| TRUE_MIN | 0.015625 | Smallest positive representable value |
Note that the number of mantissa bits MANT_DIG includes the leading one bit, regardless of whether it is explicitly stored or not. Similarly, TRUE_MIN is the smallest representable value which is usually a subnormal, but not necessarily. The constant HAS_SUBNORM indicates if subnormals are supported at all. If this is false (zero), TRUE_MIN will presumably be equal to MIN.
Another influential constant that is global to the processor architecture and (despite its name) independent of the data type, is FLT_RADIX giving the base for the floating-point representation. This is the base to which the constants MIN_EXP and MAX_EXP correspond (though this is practically always 2 these days). The decimal-base constants DIG, MIN_10_EXP and MAX_10_EXP make less precise statements about the limits of the data type, but help choose the right type based on the order of magnitude of your data.
The information contained in these constants is partly redundant. The following relations hold:

Because all values involved are representable exactly, these equivalences are also true numerically, not just mathematically.
Viewing the constants on your system
These days float.h does not contain any verbatim numbers, they are hard-coded into the C preprocessor instead, which substitutes them where used. I wrote a shell script to view the resulting constants. It supports passing the path to the C preprocessor in the CPP environment variable, which allows you to substitute the preprocessor from a crosscompiling environment to view the floating-point constants of the target architecture.
Resolution threshold
Dividing a number by EPSILON gives you an estimate of the scale at which the spacing of floating-point numbers gets larger than that number. (The result is only approximate because the spacing changes in jumps at powers of two, not continuously.) This can indicate practical limits for certain calculations. For example, using the sin() function for arguments larger than π/EPSILON may yield unexpected results, see above.
Accurate textual representation
Another standard constant helps to print out floating-point numbers in a way that allows to parse them again without loss of precision. Why would one want to do that? It can help inspect intermediate results, one could annotate them with comments, or even autogenerate a lab book.
DECIMAL_DIG gives the decimal precision you need to represent the floating-point value accurately in decimal. It is the value to choose for the precision of a printf %g output format. (Remember giving a "*" for the precision (as in "%.*g") allows to pass it in an argument after the format string.) Note that DECIMAL_DIG is always larger than DIG by two or three.
In this situation, the roles of the decimal number and floating-point representation are reversed: The floating-point datum is assumed to be exact and to be reproduced without modification from the decimal textual representation, and the decimal number has to provide enough digits to allow that. This is more feasible than the reverse problem because fractions with power-of-two denominators do not give rise to an infinite periodic string of digits in decimal.
A little-known format also deserves mention: %A outputs a floating-point
number as a hexadecimal mantissa and the exponent to base 2 (in decimal). This
representation is also exact, can be parsed by the
strtod function and is accepted in C
programs by the gcc compiler. Both %g and %A allow the prefix
L for long double arguments.
On this topic, there is some reassuring news: Floating-point operations will not crash a C program. The so-called "floating-point exeption" (the signal SIGFPE on UNIX systems) terminates programs as a consequence of integer divides-by-zero, but not floating-point operations.
Supposedly comparing a NaN will raise an exception, and avoiding that requires
using comparison
macros intended for that purpose. But in my experiments on Linux I have not
encountered any such exception, as you can verify by compiling and running
this small program.
If you want to check for floating-point error conditions, the C99 standard
offers a set of functions documented in
this manual page.
See also the more general
manual page on
mathematical functions' errors.
Some dated texts recommend disabling compiler optimisations to avoid excessive inaccuracies. This does not seem to be necessary any more. The -O flags of the Gnu C compiler do not enable any optimisations that are numerically unsafe. Those options that do have to be set explicitly. See {{https://man7.org/linux/man-pages/man1/gcc.1.html} for details.
This page should give you food for thought, but do not despair. In many if not most applications, quantities carry errors significantly larger than those incurred by floating-point arithmetic. While injudicious use of floating-point arithmetic can still degrade your results, it will not be by much. However, this does not apply where errors can accumulate, such as when iterating or accumulating, however.
Also, a surprising number of applications do not actually need floating-point numbers. Sometimes the order of magnitude of the starting data is fixed and the constant relative error floating-point numbers provide is not needed (such as when the absolute error is constant). Then for a sufficiently simple computation the orders of magnitude of the intermediate quantities and the result are also predictable. That allows you to use integers with a fixed implied denominator (potentially a different one for each quantity). This can improve accuracy, but only if you choose an integer type that is larger than the matissa of the floating-point type you would otherwise have used (>= 64 bits for practical purposes), or you want to choose a non-power-of-two denominator.
If your problem does not involve irrational numbers or transcendental functions
(which give rise to them), you may be well served by rational arithmetic. This
is usually provided by large-integer libraries such as
libgmp.
If none of the above simplifications apply to your problem, you should not just review the references below, but read a numerics book, which will tell you how to analyse it properly.
has many papers and slides about problems arising from the misimplementation
and abuse of floating-point operations by David
Goldberg — an introduction to basic properties of floating-point
arithmetic, with proofs by David Monniaux — some more potential
floating-point problems, including some specific to CPU architectures or
compilers — more elaborate and accessible advice on
floating-point data than this page
and
double
precision floating point formats gives the binary representation of these
real-life data formats.
Licensed under the Creative Commons Attribution-Share Alike 3.0 Germany License 